


Популярные задачи:
Поразрядная сортировка массива подсчетом
[Если вы еще не знакомы с поразрядной сортировкой как таковой, то быстрей прочитайте задачу поразрядная сортировка, общий принцип]
Формулировка
В классической поразрядной сортировке на каждом проходе, т.е. в пределах каждого разряда - элементы сортировались путем буквального разделения по каждому разряду, т.е. мы получали последовательности элементов, в каждой из которых содержались т.н. "одинаковые" элементы (идиентичны по конкретному текущему разряду). Очевидно, что для того, чтобы получить единую последовательность элементов отсортированных в пределах одного этого разряда - надо просто один за другой, по-порядку соединить все эти последовательности между собой.
Подход, о котором идет речь здесь - отличается тем, что на каждом проходе элементы исходной последовательности сортируются по конкретному текущему разряду не с помощью разделения по карманам, а с помощью подсчета элементов, которые меньше индекса некоторого дополнительного массива счетчиков. Т.е. никаких уже 2 этапов: распределения и сборки. Теперь можно сказать - только подсчет и вставка элементов в нужное место.
Подробнее. Те же основные итерации по каждому разряду максимально-разрядного числа, от младшего к старшему разряду. В пределах каждой итерации - составляем последовательность(назовем ее positions) из значений разрядов каждого элемента нашей последовательности, чтобы только с этими значениями на данной итерации и работать (сами числа нам не нужны конечно - только текущие их разряды). Далее составляем искомый массив счетчиков - count, размером range. Каждое его значение будет определять количество элементов из positions, которые меньше индекса данного элемента массива count. После того, как такой массив будет составлен - мы будем знать где на самом деле на данной итерации должен находится каждый элемент из positions, чтобы последний был отсортирован, поскольку для каждого элемента positions мы знаем количество элементов меньших чем он и поэтому встравляем его на соответствующее место.
Пример.
Пусть имеем исходную последовательность из 10-ти элементов source = {3, 1, 3, 9, 1, 4, 3, 2, 8, 3}.
Т.о. range = 10, width = 1, n = 10.
Составляем массив count размера range, т.е. в данном случае - 10. Пока инициируем его нулями. Далее проходимся по source от начала и до конца и для каждого его значения - просто увеличиваем(инкрементируем) соответствующий элемент count, что-то вроде:
for i = 0 to n-1
count[ source[i] ]++
Получаем: count = {0 2 1 4 1 0 0 0 1 1}
Далее проходимся по count и для каждого элемента считаем сумму предыдущих:
count[i] = count[0] + count[1] + ... + count[i-1]
В нашем случае получим: count = {0 0 2 3 7 8 8 8 8 9} Т.е. каждый count[i] - это количество элементов, меньших i. Это и является ключом метода. Теперь мы проходимся по всем source[i] и зная количество элементов меньших source[i]: count[ source[i] ](=K например) - просто вставляем source[i] на следующую позицию: K+1.
На этом, по-сути, сортировка для данного примера и заканчивается, т.е. имеем здесь только одну главную итерацию алгоритма, т.к. максимальное количество разрядов(width) = 1. Если бы в исходном массиве были бы двухзначные числа(56, 35), то имел бы место еще один проход, который бы отличался только тем, что на нем рассматривался бы еще и второй, более старший разряд элементов(ключей).
Т.о. получаем, скорость ~ О(width*(2n + range)), память: ~(2n + range).
Оптимизация
Формирование ключевых массивов count можно начать заранее. Т.е. до запуска алгоритма, пробежавшись по нашему исходному массиву x - можно "наполовину" рассчитать все массивы count для каждого разряда, потому что неважно как расположены числа: количество одинаковых чисел по разрядам не меняется на каждом проходе. Поэтому если до основного цикла рассчитать все эти массивы count - на каждом проходе будет делаться лишь (n + range) операций, а не (2*n + range):
Т.о. получаем, сокращение скорости до: ~ O((width + 1)*(n + range)), но увеличение памяти до: ~(2n + width*range). Глядя на эту новую пропорцию скорости - выигрышь в производительности представляется не очень очевидным, но чисто логически рассуждая можно прийти к выводу, что общее количество проходов по исходному массиву x размера n - сокращается: с ~ 2*width*n, до (width + 1)*n.
Сравнительные диаграммы
Представляя на графиках производительности обеих алгоритмов(Graph1) и их отношение(т.е. насколько оптимизированная версия быстрее, Graph2) в зависимости от размера массива - n (при width=2, range=10), получим:
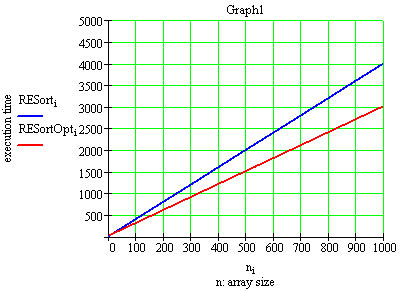
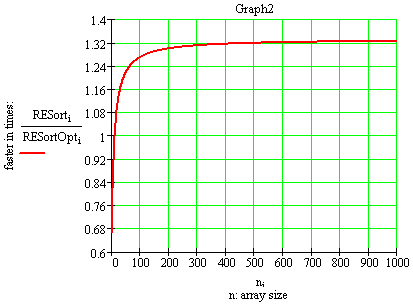
Как видим, наибольший выигрышь в скорости достигается на больших размерностях массива(>200). На малых же размерностях данная версия менее производительна(Graph3):
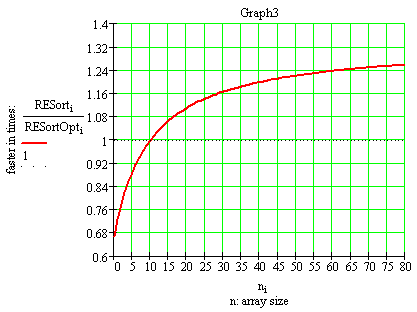
Точка перелома(n=10 в данном случае) очевидно определяется значениями width и range.
Что же касается увеличения расхода памяти, то при тех же условиях получим:

Т.е. на некоторую постоянную величину(определяющуюся значениями width и range) памяти будет расходоваться больше.
Реализации:
C++(2) +добавить1) неоптимизированная версия на C++, code #10[автор:this]
2) оптимизированная версия на C++, code #11[автор:this]